|
To access the population analysis function:
| • | Click Print then Reports then Population analysis on the menu bar. |
Each time you perform serum level analysis, the calculated pk parameters are saved. This data is a virtual gold mine of information about your patient population. With this tool you can derive a model better fitted to your patients.
How-to
First, select a model to analyze from the drop down list, then select a date range. The remainder of the criteria are optional. You may use these optional criteria to further narrow down the population analysis:
Area
This keys on the "location" field in your patient data, which may not be applicable to your practice situation. For example, if all your ICU beds start with ICU, then select "Specific" and enter ICU in the input box. This will limit the analysis to all patients whose locations *start* with ICU. The important point to remember is, the program matches your criteria with the start of the location field.
Age
You may choose to select an age range to analyze.
Gender
You may choose to select a specific gender to analyze.
Creatinine clearance
You may choose to select a creatinine clearance range to analyze.
Analyze
Click this button to analyze the data and print a summary report. Information included in this report are:
| • | Mean Volume of distribution and descriptive statistics |
| • | Regression equation of CrCl vs Kel and descriptive statistics |
| • | Regression plot |
The volume of distribution analysis calculates the population Mean Vd, standard deviation, range, and the following descriptive statistics:
Skewness
Skewness is a measure of the asymmetry of the data around the sample mean. If skewness is negative, the data are spread out more to the left of the mean than to the right. If skewness is positive, the data are spread out more to the right. The skewness of the normal distribution (or any perfectly symmetric distribution) is zero. As a general rule of thumb:
| • | If skewness is less than -1 or greater than +1, the distribution is highly skewed. |
| • | If skewness is between -1 and -½ or between +½ and +1, the distribution is moderately skewed. |
| • | If skewness is between -½ and +½, the distribution is approximately symmetric. |
Kurtosis
Kurtosis is a measure of how outlier-prone a distribution is. The kurtosis of the normal distribution is 0. Distributions that are more outlier-prone than the normal distribution have kurtosis greater than 0. A higher kurtosis means more of the variance is the result of infrequent extreme deviation, i.e., extreme values are more likely.
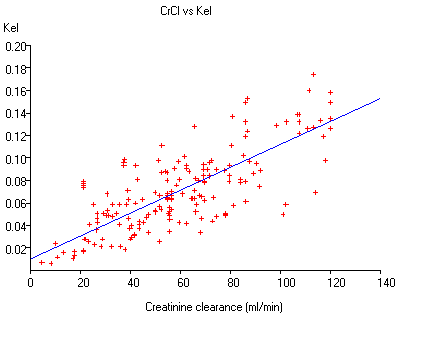
Least squares linear regression is used to analyze CrCl vs Kel. The y-intercept of this regression line is the Nonrenal K, the slope of the line is the Renal K. The following descriptive statistics are also calculated:
Standard error of estimate
The standard error of estimate is analogous to standard deviation, indicating data spread. It is an estimate of the accuracy of the regression equation.
Coefficient of correlation (R)
The correlation coefficient s a measure of the correlation (linear dependence) between two variables. R ranges from -1 to 1. A value of 1 implies that a linear equation describes the relationship between X and Y perfectly, with all data points lying on a line for which Y increases as X increases. A value of -1 implies that all data points lie on a line for which Y decreases as X increases. A value of 0 implies that there is no linear correlation between the variables.
Coefficient of determination (R-squared)
The coefficient of determination quantifies the overall quality of the fit of the regression line. R-squared can be thought of as a percent. Roughly speaking, it tells how many of the points of data fall within the results of the line formed by the regression equation. The higher the coefficient, the higher percentage of points the line passes through when the data points and line are plotted. If the coefficient is 0.80, then 80% of the points should fall within the regression line. Values of 1 or 0 would indicate the regression line represents all or none of the data, respectively. A higher coefficient is an indicator of a better goodness of fit for the observations.
Regression plot
A plot of this regression analysis displays the computed regression line and all data points.
Export
Click this button to save the data to a CSV file which can be read by a spreadsheet program such as Excel. This allows you to further manipulate and analyze the data within a spreadsheet.
Error messages
Y-intercept less than zero is displayed when the regression line intercepts the Y axis below zero.
Regression analysis yielded a negative slope is displayed when the regression line is inverted.
The regression line is a plot of X vs Y where X is creatinine clearance (the independent variable) and Y is the elimination rate (the dependent variable). The Y intercept is the Nonrenal Kel, the slope of the regression line is the Renal Kel for the following equation:
Kel = NonRenalK + [CrCl x RenalK]
It would be impossible (of course) for there to be a negative NonRenal Kel, that would mean you are somehow putting drug back into the system instead of excreting it. Likewise, a negative slope would indicate an inverse relationship with creatinine clearance.
Both of these "errors" are caused by a widely scattered data set for which a regression line cannot be accurately calculated. This would be expected with a drug like Vancomycin which has a wide variability in pk parameters. Usually it takes a higher N in your data set before the data becomes analyzable. Keep saving your consults and eventually you will acquire a data set that will give usable results.